
Does Automation Win? HITL Machine Learning Proves Otherwise.
Why Human-in-the-Loop Data Annotation Still Outperforms AI Automation
We are drowning in data today. Artificial intelligence continues to mature and needs more and more data to handle every voice command to Alexa, every medical scan, and every uploaded photo. In 2024, we created over 149 zettabytes of information, and it's more than during the entire previous decade. But raw data is nothing. It's like a huge library where the books have no titles or are piled in a mess. AI can learn only from accurately organized data, so someone needs to label it.
You may think it’s a perfect task for AI itself, right? Many companies have switched to fully automated annotation systems that work 24/7 without coffee breaks or sick days. However, don’t forget about AI imperfections. It can misread sarcasm, miss cultural nuances, or fail to recognize rare but critical anomalies. That's why the smartest companies haven't abandoned humans. HITL machine learning is not a holdover from the past but a modern strategy that combines machine efficiency with human insight.
In this article, we’ll explore why HITL machine learning often works better than full automation. You’ll see where human input matters most, how human-machine collaboration works, and why world giants still have armies of human annotators working behind the scenes.
Why Fully Automated Annotation Is Not Enough
Even the most advanced AI systems have limits. Fully automated annotation may be fast, but it often stumbles when accuracy, fairness, and real-world complexity are at stake. What exactly is at risk?
Lack of Contextual Nuance
AI models can misinterpret language and visual cues when they don’t fully understand context. For instance, sarcasm in text often eludes automated sentiment analysis tools. Studies reveal that AI struggles with sarcasm detection. It does not fully grasp the nuanced tone in sarcastic remarks. Simply put, an automated system may see the word “great” and think a tweet like “Great, another Monday morning meeting” is happy. But a person understands it’s actually sarcastic and means the opposite.
The same happens with visual data. AI can misclassify objects when it deals with ambiguous or partially obscured images. Another study found that self-driving cars have trouble seeing lane lines and traffic signs when it snows, which can cause mistakes and safety risks.
Unfair Decisions
Automated systems can repeat and even increase biases that are present in their training data. A study found that AI resume screening tools showed serious racial and gender biases. They often choose resumes with names associated with white and male applicants and ignore those linked to black and female candidates.
Furthermore, facial recognition technologies make errors when dealing with individuals with darker skin tones. Such biases can lead to frustrating discriminatory outcomes.
Edge Case Failures
AI often fails when it faces uncommon scenarios, for example, a strange medical issue or a blurry object in a photo. It happens because it hasn’t seen enough examples. AI translation tools make serious mistakes in legal and medical documents. Most often, they misunderstood unclear wording or common expressions.
That’s why AI is excellent for speed, but humans still need to check and fix mistakes, especially in important areas like healthcare.
What is Human-in-the-Loop Annotation?
Human-in-the-loop (HITL) annotation blends artificial intelligence with human expertise. HITL workflows don’t rely entirely on automation and include trained annotators who review and improve machine-generated labels. HITL machine learning delivers more accurate, consistent, and reliable data. And this is critical for complex or high-stakes use cases.
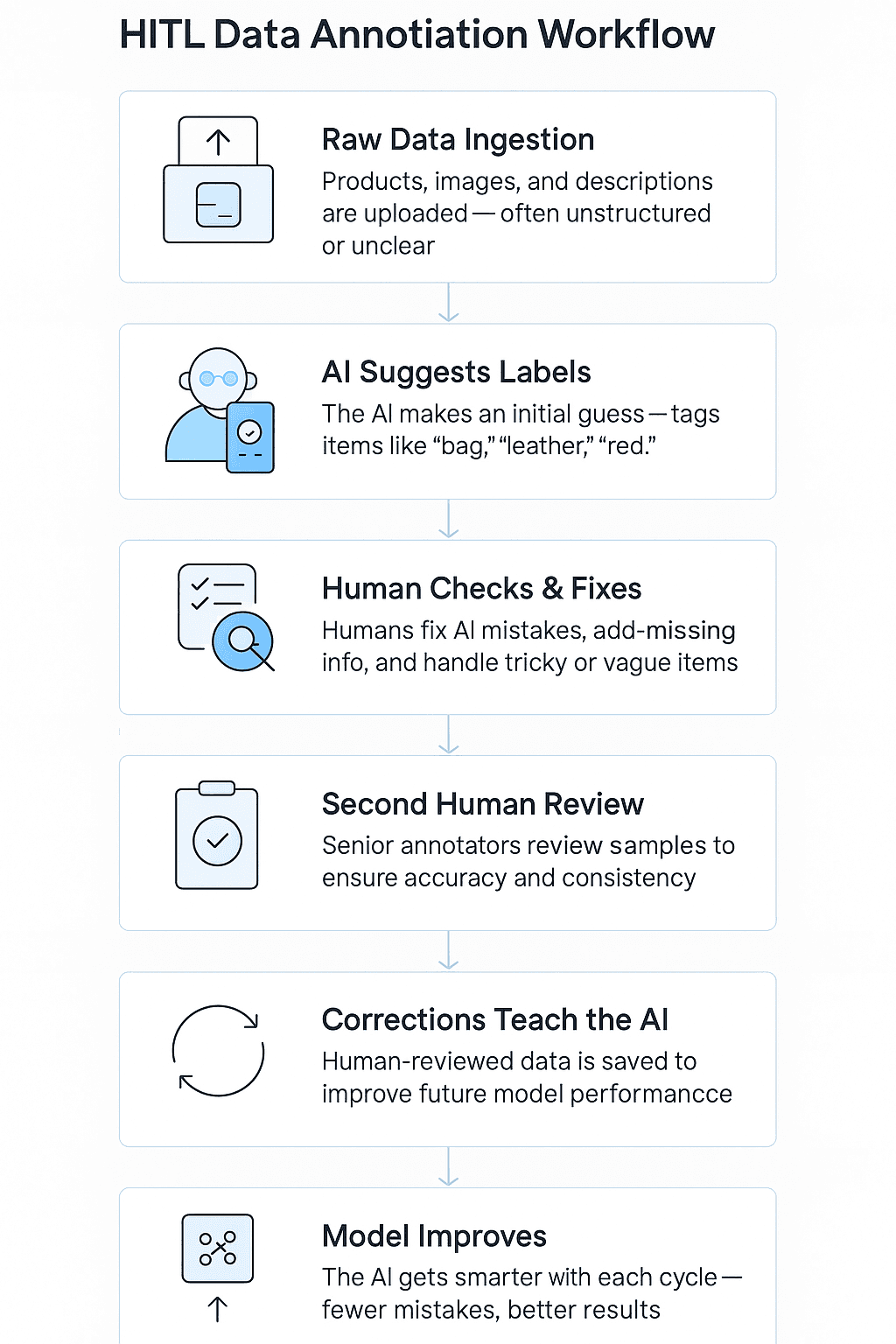
What does a typical HITL annotation workflow look like? Here’s how a HITL data annotation process of a real-world marketplace like Amazon or Etsy may look.
1. Input stage
Sellers constantly add new products. They upload images, text, and other details. These usually include different data types - images, text descriptions, dimensions, pricing, and even multilingual content. This incoming data is often messy and chaotic. Images are low-resolution or misaligned, and descriptions are vague or incomplete. Before the actual labeling, this raw data has to be collected and sent into the system for processing.
2. AI pre-annotation
At this stage, AI models take the first look at the data. They scan images to guess product types (like shoes or bags) and look at text to pull out key features. When it comes to goods, it can be color, size, or material. Let’s take a red leather crossbody bag title. The system will tag it as “bag,” “leather,” and “red.” It speeds things up, but not always without mistakes, unfortunately.
3. Human review
Now, it’s a turn for HITL machine learning. Humans check how AI performed. They fix mistakes, such as color nuance or add additional tags like “women’s accessories.” If the product is unusual or hard to classify, the human will use their own judgment and suggestions. This part of the workflow is critical when AI gets confused by blurry photos or mixed items.
4. Quality control
After human annotators finish their work, experienced team members double-check a sample of the annotations. They’re not looking at every single label, however, they will easily catch common issues. Their job is to keep the company’s standards. For example, they check that the right categories are used and brand names are spelled correctly
5. Feedback integration
After the approval, updated labels are saved and added to the training data. This step enables AI to learn from its past mistakes. For example, if it keeps confusing color shades, the corrected examples will explain the differences in a clearer way. Over time, this feedback trains AI to make more precise labels and fewer errors.
6. Model retraining
AI gets updated every time it receives new information. Over time, it becomes more accurate and needs fewer revisions and amendments. It improves its understanding of product categories, regional language nuances, and even seasonal items. However, humans still stay in the loop for tricky or unusual cases.
5 Reasons HITL Data Annotation Still Beats Full Automation
Google, Amazon, Meta, and Microsoft still use human annotation teams. They know that automation alone can’t guarantee reliable results. When an autonomous vehicle misreads a snowy stop sign, the cost is not a mislabeled image but a potential life at risk. So, they use humans for content moderation, search results, and recommendations - people improve accuracy and reduce mistakes.
In healthcare, insurance, and finance, laws often require human oversight. Annotators help make sure the data follows rules and meets ethical standards. And this is not optional – humans in the loop bring undeniable benefits:
Accuracy & Context Nuances
Machines spot patterns with no mistakes, but they do not always fully understand the meaning. Language is full of subtleties, sarcasm, and double meanings, and AI often misreads these. People understand sarcasm, idioms, and cultural references much better than machines. They can interpret product nuances, abbreviations, or jargon naturally. Humans also differentiate irony and genuine sentiment.
Uber has launched its official HITL platform, uLabel, to help with e-commerce data annotation. It tags products, fixes mislabeled categories, and interprets confusing context or regional slang. Their documentation highlights how human review corrects AI mislabels and improves dataset quality.
Edge Case Handling
AI systems usually struggle when they meet scenarios they haven’t seen before. These edge cases often happen in medicine, finance, or autonomous driving. An unusual skin shade, a rarely used legal clause, or an object hidden in a snowstorm may confuse even the best-trained model. Humans better handle such situations. They analyze first and then interpret. It makes HITL workflows much more reliable when things get complicated.
Tesla's assembly line robots have faced challenges when components were slightly misaligned. This issue appeared during the production of the Model 3. The company admitted that it had relied too heavily on automation, which led to delays and quality issues. The role of humans was underrated.
Bias Detection & Ethical Oversight
Bias in AI is not unintentional, but it is still damaging. If an AI tool is trained on biased data, it can reinforce discrimination. For instance, a hiring algorithm may select resumes with names linked to a particular gender or ethnicity. Human reviewers spot these issues and intervene. They act as ethical checkpoints and restore fairness. It’s critical in many fields.
When Amazon's AI revealed discrimination against resumes containing “women’s”, the company paused the system and introduced human annotators to identify, correct, and retrain the model to eliminate gender bias. This remains one of the most cited official cases of how HITL data annotation corrected AI fairness issues.
Adaptability to New Domains
AI models take time to adapt to new industries or datasets. But HITL workflows adapt very quickly. Human annotators immediately fill the gaps when entering a new market or launching a product with unfamiliar data types. AI immediately catches up after human adjustments. This flexibility makes HITL ideal for startups and enterprise teams.
Hummingbird officially used CloudFactory's HITL annotation services to label agricultural drone imagery and identify plant health and soil characteristics. Their published case study describes how HITL machine learning rapidly adapted to crop-specific labels that AI models initially struggled with.
Feedback Loop for Model Training
HITL systems do more than error correction - they actively teach the model. Every corrected label becomes training fuel. Over time, this improves AI performance and reduces future mistakes. People stand behind a continuous cycle of learning and refinement.
Self-driving data from Tesla Autopilot found that mistakes considerably drop when AI systems are combined with human oversight. Humans step in when the system gets confused by bad weather or unclear road signs. This illustrates why people in the loop are irreplaceable.
The Role of Outsourcing in HITL Success
HITL machine learning involves skilled people who professionally review and correct data. However, it’s hard and expensive to build and manage a large in-house annotation team. That’s why many companies prefer to outsource this part of the process.
The main advantage of outsourcing is flexibility. You avoid the headache of hiring and training a big internal team and can delegate HITL data annotation tasks to experienced partners with relevant expertise. These teams provide a wide range of data annotation services – they tag images, label videos, moderate content, or review product listings.
Hiring a third-party annotation service lowers costs, provides access to specialized talent across different domains, and often offers the ability to operate 24/7. It’s perfect for global projects with tight deadlines. Plus, partners with domain expertise can better capture subtle nuances in data.
Outsourcing is also a great solution when you deal with global or multilingual content. Local teams better understand cultural context, tone, and language differences. For example, a sentiment analysis model trained only on English data may misread humor or slang in Spanish or Arabic. But native-speaking annotators catch and correct these nuances easily.
Another key benefit is quality control. Strong annotation partners offer built-in review systems and feedback loops so that the data meets high standards. The Tinkogroup team, for instance, does not simply label the data. Its staff is trained to work closely with machine learning engineers, provide regular updates, and improve model accuracy over time.
Outsourcing saves time and money, and not only that. With the right HITL machine learning partner, you will improve the accuracy of your AI systems and still keep a high level of efficiency.
Conclusion
What’s the verdict on the above? AI won’t fully replace humans like many people think. The task is to make humans and machines work together seamlessly. Full automation seems tempting, but the leading companies understand that true quality comes from collaboration between people and AI. HITL data annotation is not a backup for AI but its strategic advantage. It enhances accuracy, uncovers hidden biases, and allows models to adapt quickly in unique situations.
If you’re looking for annotation services, choose companies that use HITL machine learning. This approach gives you more control and confidence that your AI will be smarter, fairer, and more reliable. AI is penetrating into more parts of our lives, but a human touch remains essential. So, human-in-the-loop isn’t only a good practice - it’s the key to building AI we can truly trust.
